
From Collection to Control
Fixing data after it’s been collected is slow, expensive, and unreliable. We explore why organisations across agriculture and the food chain must shift from reactive clean-up to controlled, validated data collection at the point of entry.
Most supply chain data problems start long before analysis.
They start at the point of collection.
Across agriculture and food production, organisations still rely heavily on spreadsheets, email attachments, and manually consolidated submissions to collect critical operational data.
What begins as a practical workaround quickly becomes a bottleneck with:
Inconsistent formats
Missing fields
Delayed submissions
Version control issues
Endless manual validation
The result is predictable. Teams spend more time preparing data than using it.
And no matter how sophisticated the reporting layer becomes, poor collection processes continue to undermine the quality, speed, and trustworthiness of the final output.
This is exactly the problem YAGRO Exchange is designed to solve. Because if data is not structured correctly at the point of entry, no dashboard or analytics layer can fully repair it later.
The wrong place to solve the problem
When organisations struggle with fragmented or unreliable data, the instinct is often to improve reporting. Build another dashboard. Add more analytics. Create more visualisations.
But better reporting does not fix poor data. It simply exposes the problems more clearly.
If data is incomplete or inconsistent before analysis begins, the issue has already happened. By the time teams discover missing information or formatting issues, the opportunity to correct them is often gone. And once trust in the underlying data is compromised, decision-making slows down.
Why spreadsheets stop scaling
Spreadsheets remain deeply embedded within supply chain operations because they are flexible, familiar, and easy to distribute.
But they were never designed to operate as large-scale, multi-user collection systems across interconnected businesses.
As programmes grow, the limitations become obvious:
No standardised structure across contributors
No validation during submission
No visibility of completion progress
No reliable version control
No enforcement of data completeness
What started as a workaround becomes operationally fragile. A single missing file can delay an entire programme. Errors are often only discovered once analysis begins, creating significant delays and rework. The problem is not spreadsheets themselves. It is relying on them as infrastructure.
Rethinking data collection
Forward-thinking organisations are starting to treat data collection differently. As a structured workflow. One where:
Data is captured consistently
Validation happens during entry
Submission progress is visible in real time
Data becomes immediately usable
This is not just about efficiency. It is about creating trust and control before analysis even begins.
From fragmented collection to structured workflows
YAGRO Exchange was built specifically for this shift.
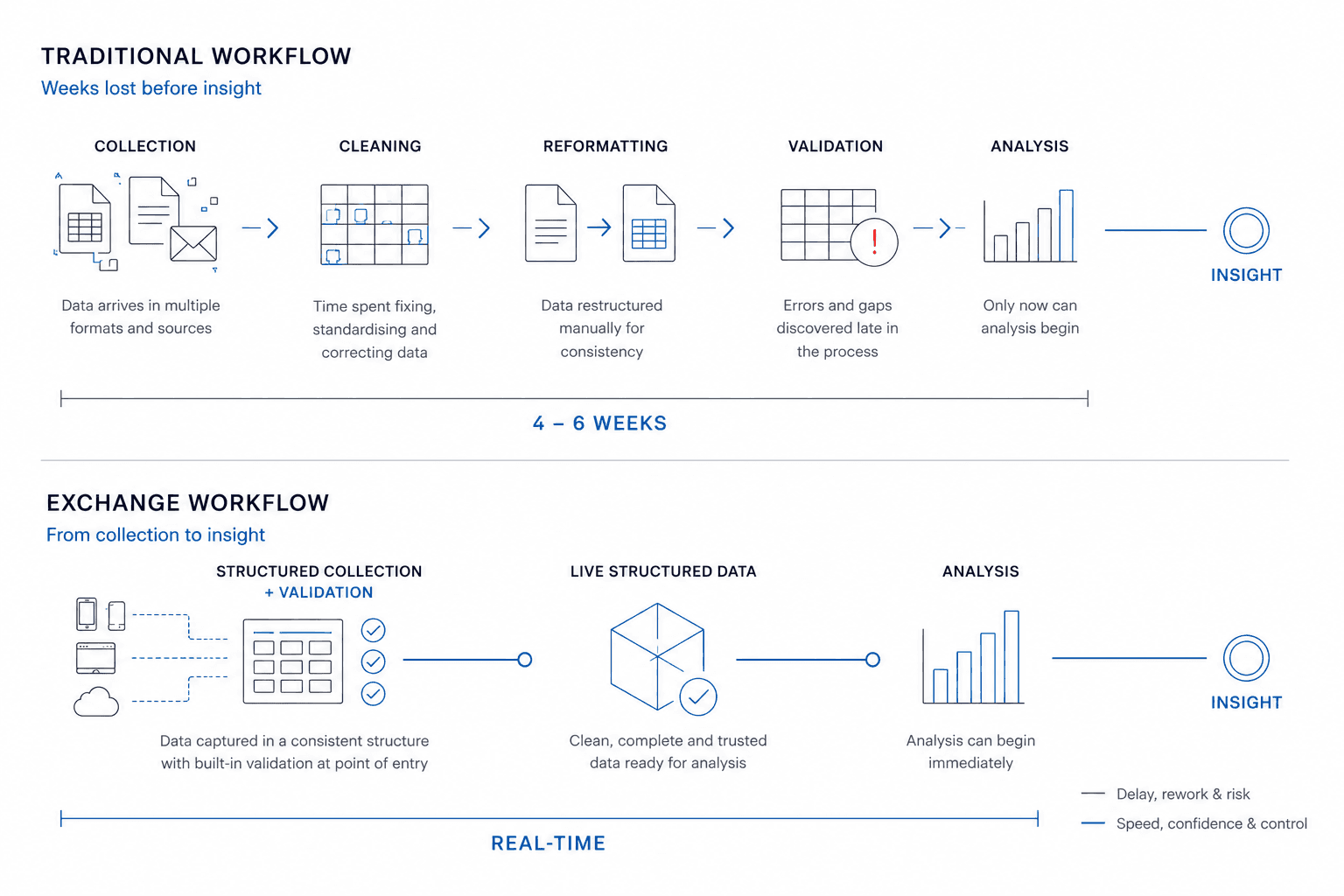
Instead of fragmented spreadsheets and disconnected submissions, Exchange provides a structured environment for collecting operational, financial, sustainability, and supply chain data at scale.
Data is submitted once, within a clearly defined structure. Validation happens during submission, not weeks later during analysis. Programme managers gain real-time visibility across contributors, submissions, and data quality.
The impact is immediate:
No version control chaos
No manual consolidation
No endless reformatting
No discovering critical errors late in the process
Instead, organisations receive structured, validated, analysis-ready data from day one.
Removing time from the process
When collection becomes structured, something fundamental changes. Time disappears from the workflow. Weeks previously spent gathering, correcting, restructuring, and validating data are removed. Analysis can begin immediately. Insight becomes current rather than retrospective. And data starts supporting decisions in real time, not weeks after the opportunity to act has passed.
More than moving away from spreadsheets
This is not simply a transition from spreadsheets to software.
It is a shift from:
Manual workflows to governed systems
Individual ownership to organisational visibility
Fragmented processes to connected data flows
Delayed reporting to real-time operational intelligence
In other words:
From collection to control.
What comes next
Once data is structured and validated at the point of collection, a much bigger opportunity opens up. Data can be standardised across organisations, connected across supply chains, and transformed into comparable, decision-ready intelligence.
In the next article, we’ll explore why clean data still is not enough, and how canonical data models, powered through platforms like YAGRO IQ, enable organisations to turn fragmented datasets into trusted supply chain intelligence at scale.




