
A Shared Language for Data
Canonical data models are essential for turning fragmented supply chain data into consistent, comparable, and reliable intelligence. We explore how these systems enable scalable analysis and confident decision making.
Why Canonical Data Models Unlock Supply Chain Intelligence
In the previous article, we explored how organisations are rethinking data collection; moving away from spreadsheets and towards structured, validated inputs at the point of entry.
That shift solves a critical problem. But it doesn’t solve everything.
Because even when data is clean, consistent, and complete, another challenge remains: It still doesn’t speak the same language.
The next barrier; inconsistency at scale

Across the supply chain, different organisations capture similar data in very different ways.
The same concept can appear in multiple forms:
Yield recorded in tonnes, tonnes per hectare, or even bushels
Costs split differently across operations, inputs, and overheads
Field names, crop names, and identifiers structured inconsistently
Time periods defined differently across businesses
Individually, each dataset makes sense.
But when brought together, inconsistencies begin to compound.
Data becomes difficult to compare. Harder to aggregate. And increasingly unreliable as a foundation for decision making.
This is where many data initiatives stall. Because connecting data is only part of the problem. Making it comparable is the next.
Why standardisation isn’t enough
A common response is to try and standardise data.
Define templates. Align formats. Create shared definitions.
But in practice, this rarely holds up under the pressure of larger datasets.
Different systems, organisations, and use cases continue to generate variation.
Edge cases emerge. New data types are introduced. Standardisation becomes brittle.
What’s needed is something more flexible, but more robust.
Introducing canonical data models
A canonical data model provides a different approach.
Instead of forcing every system to produce data in the same format, a canonical model acts as a common structure into which all data is mapped.
It creates a shared language.
No matter how data is captured, sourced, or formatted, it is translated into a consistent, governed structure before it is used.
This is the foundation for scalable data systems.
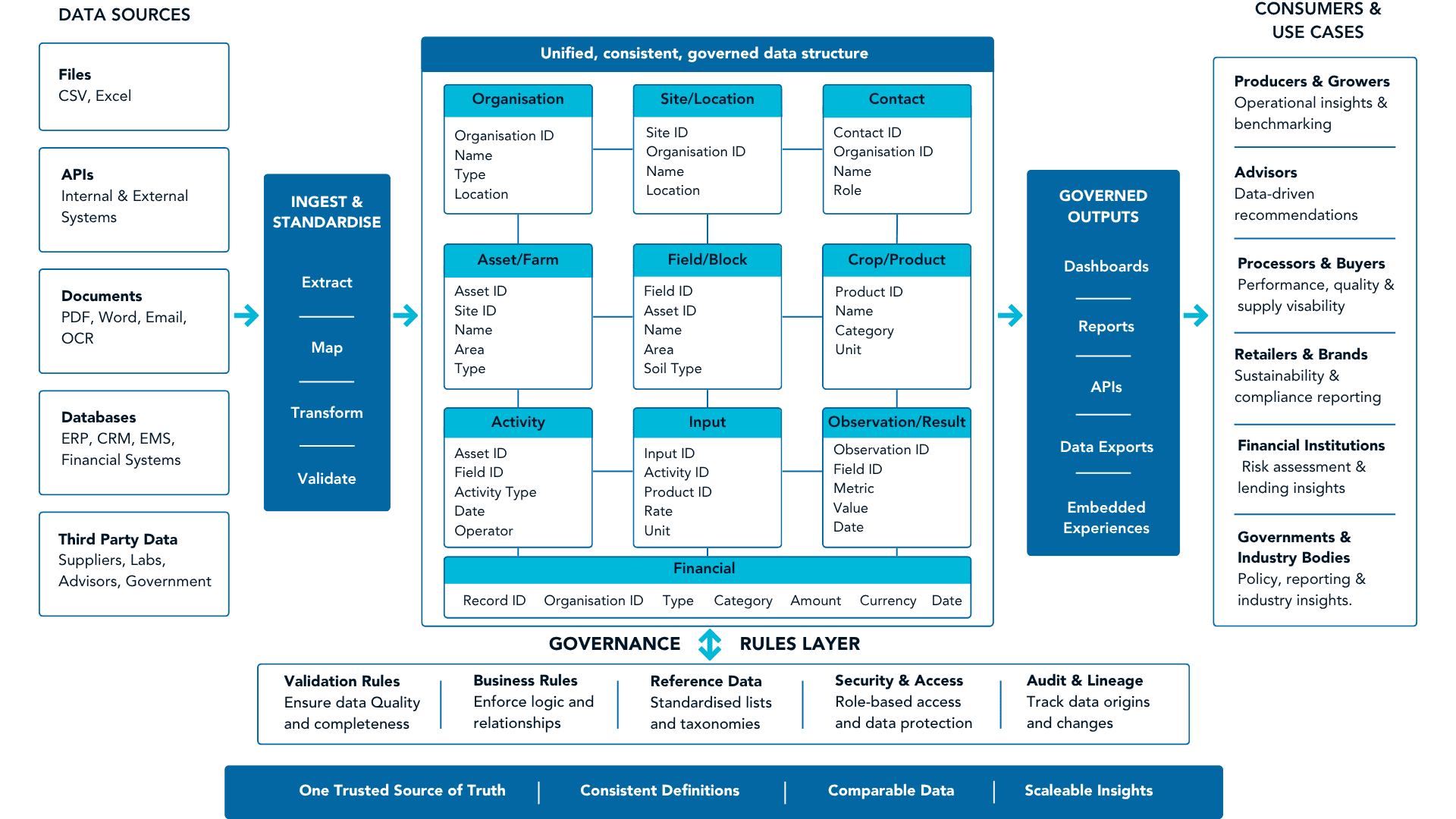
From fragmented inputs to governed outputs
At its simplest, a canonical model does three things:
Structures data consistently
Inputs from APIs, spreadsheets, documents, and external systems are mapped into a unified formatApplies rules and logic
Data is validated, filtered, and interpreted using defined rulesEnables repeatable outputs
Calculations, benchmarks, and insights are generated consistently, every time
This is the model behind platforms like YAGRO IQ, where data from multiple sources is ingested, structured, validated, and transformed into governed outputs.
The result is not just connected data, but usable intelligence.
Why this matters in practice
Without a canonical model, every analysis becomes a one off exercise.
Data has to be reinterpreted each time. Definitions are debated. Outputs vary depending on who is doing the work.
With a canonical model in place:
Calculations are applied consistently
Definitions are fixed and transparent
Outputs are repeatable and comparable
This changes the nature of decision making. Organisations move from “Is this comparable?” to “What does this tell us?”
Context matters
One of the most important aspects of a canonical model is that it doesn’t treat all data equally. It understands context.
Rules can be applied to:
Validate completeness and quality
Weight more reliable or relevant inputs
Filter data based on geography, crop, or system
Exclude outliers or unsuitable records
This ensures that outputs are not just consistent, but credible.
Reliable outputs, not just plausible ones.




